WinterWxLuvr
-
Posts
29,279 -
Joined
-
Last visited
Content Type
Profiles
Blogs
Forums
American Weather
Media Demo
Store
Gallery
Everything posted by WinterWxLuvr
-
Wouldn’t take much
-

Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
Not I -
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
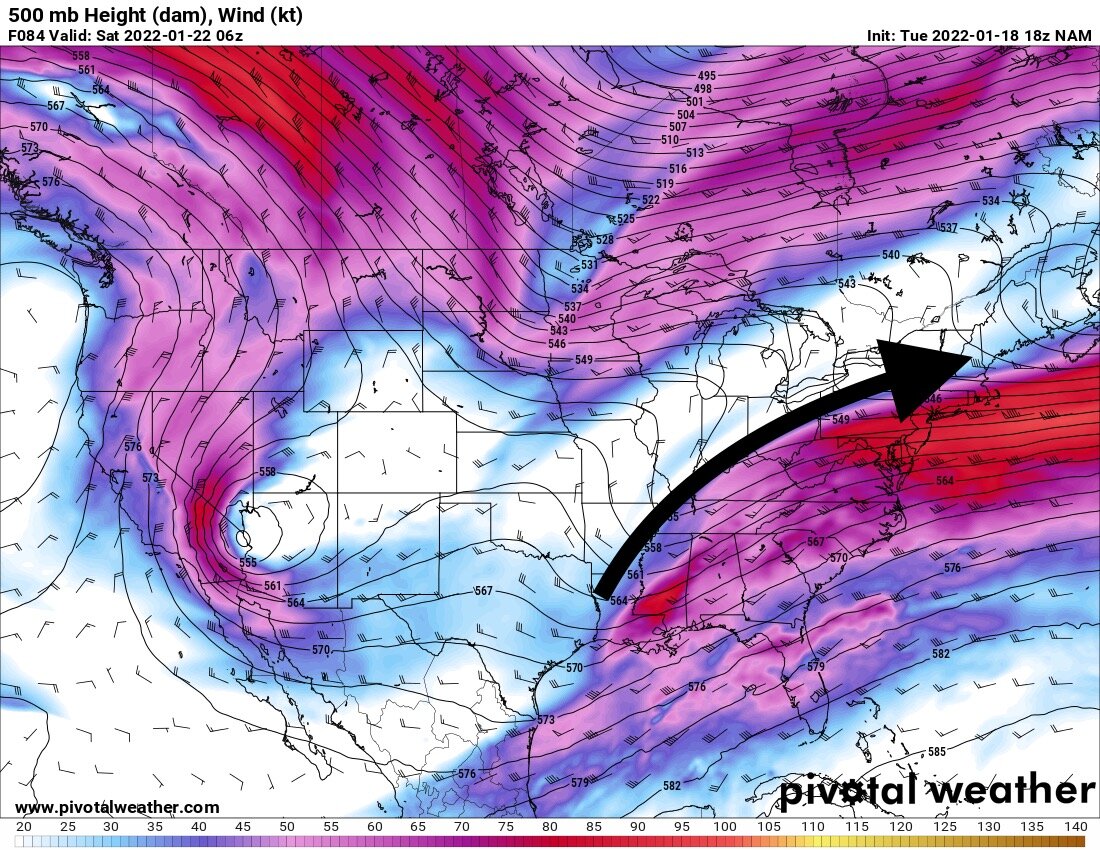
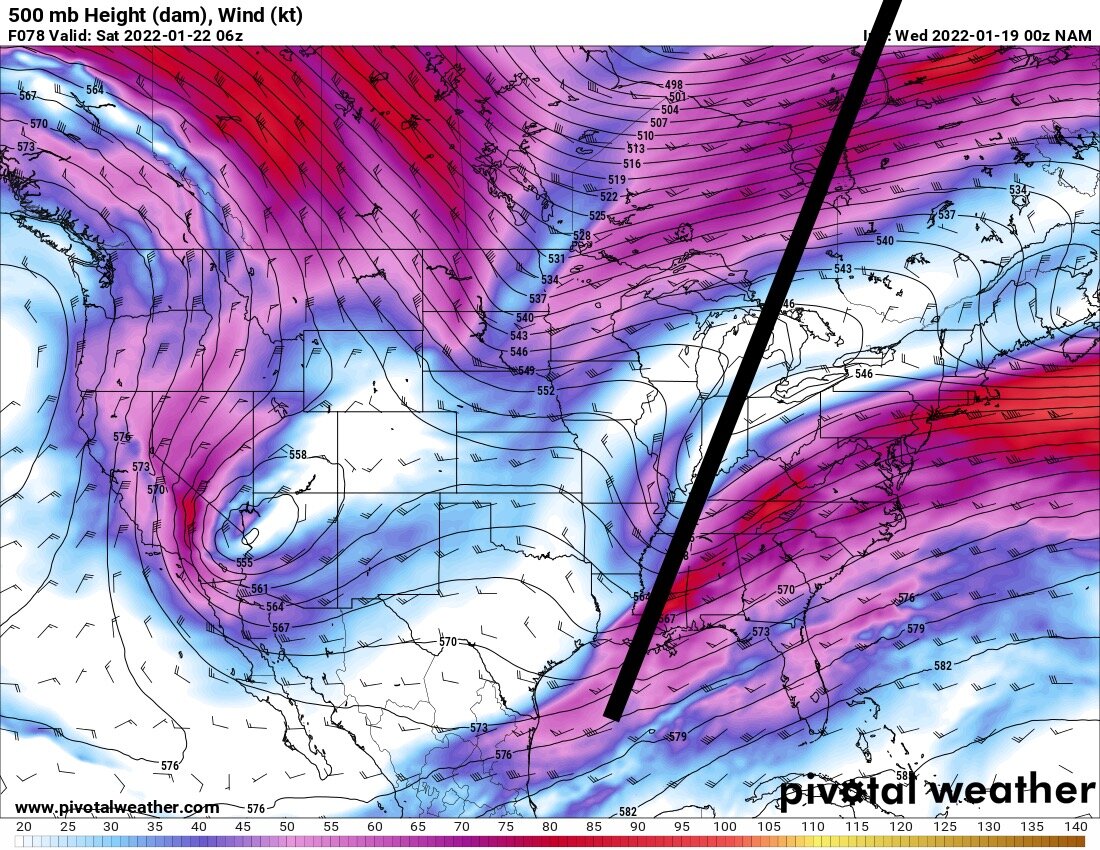
Much better. Deeper and slower. I was using the 549 height line for reference. At 0z Friday night (Sat) it was just north of Nashville on this run and in the prior run it was just south of Huntington. That’s a big difference. -
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
Yeah those weren’t correct -
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
I won $50 -
Thursday 1/20/22 Stat Padder Discussion and Observations
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
ICON is better for this -
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
Yeah, ICON is too progressive -
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
$50 says the ICON on TT freezes up and doesn’t show h5 at 54-78 -
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
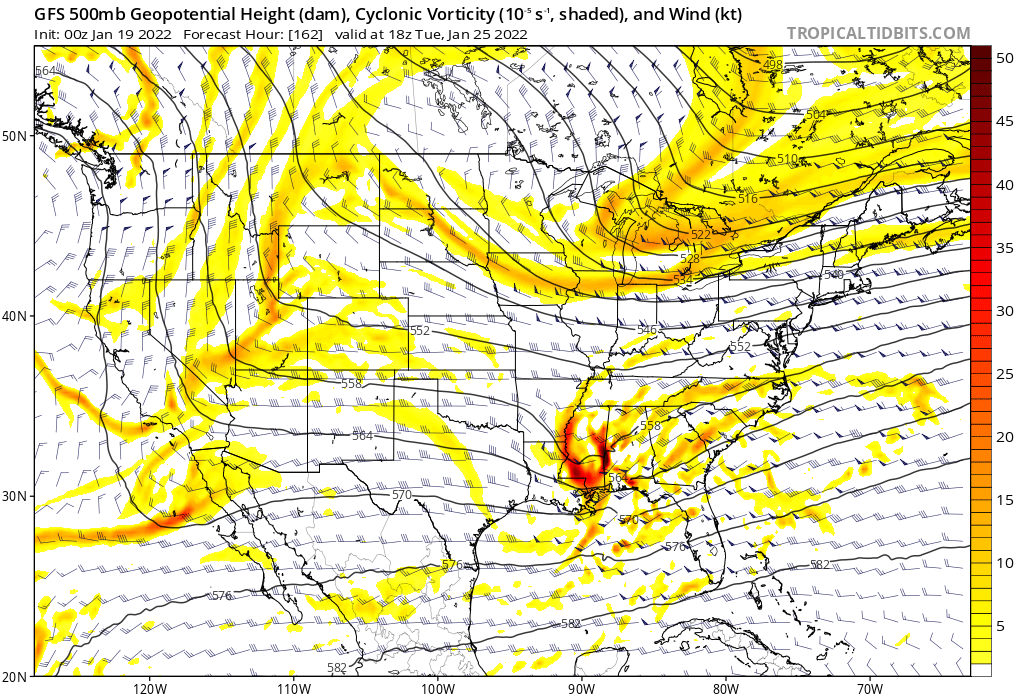
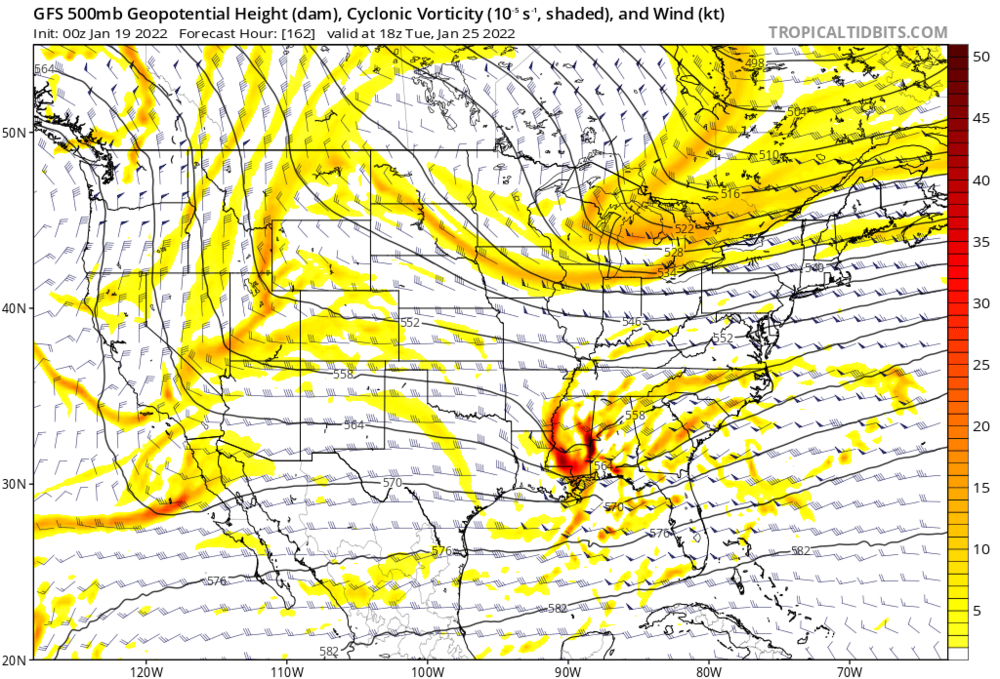
This is an interesting post. I was looking at the North America h5 maps on the gfs earlier and something really stood out. At that range (view) when you toggled back 4,5,6 runs you couldn’t tell any real difference. Made me realize that it comes down to very small features when you’re looking at the practical weather at any specific time. So I can see a scenario where a model may score well on a large scale evaluation but poorly on the small scale that actually determines the real weather you get. -
Thursday 1/20/22 Stat Padder Discussion and Observations
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
When are warnings coming out -
There’s joy in Mudville again
-
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
We get that line to vertical .. maybe 6 hours earlier and 50-75 miles farther west … game on -
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
Plain. All I did was connect valleys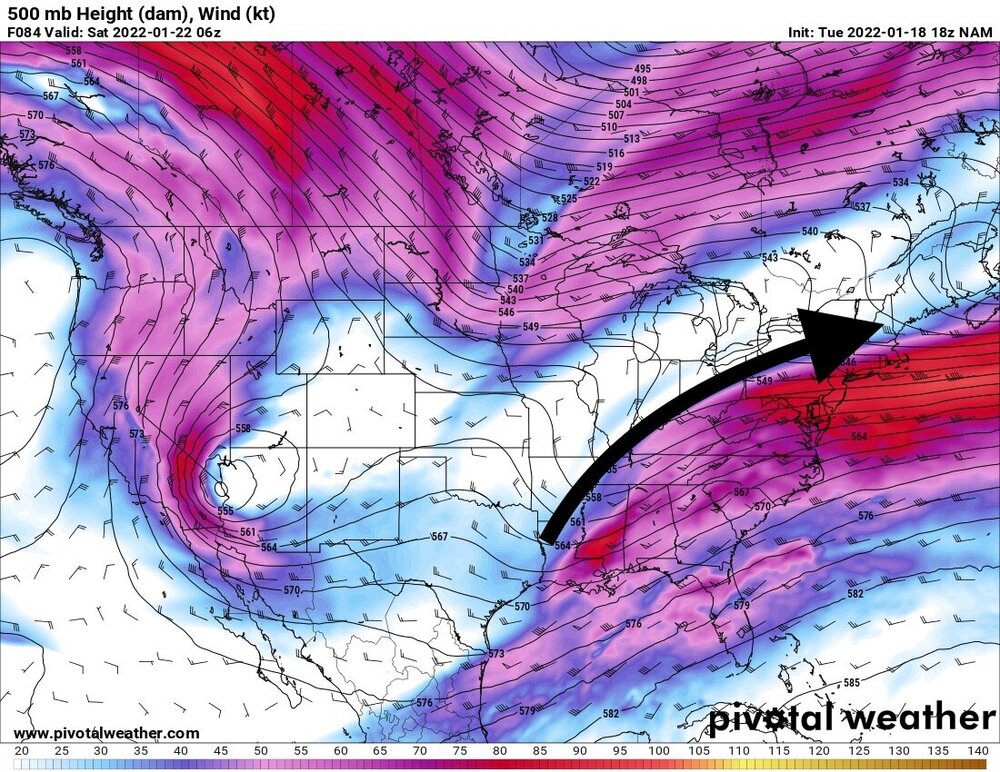
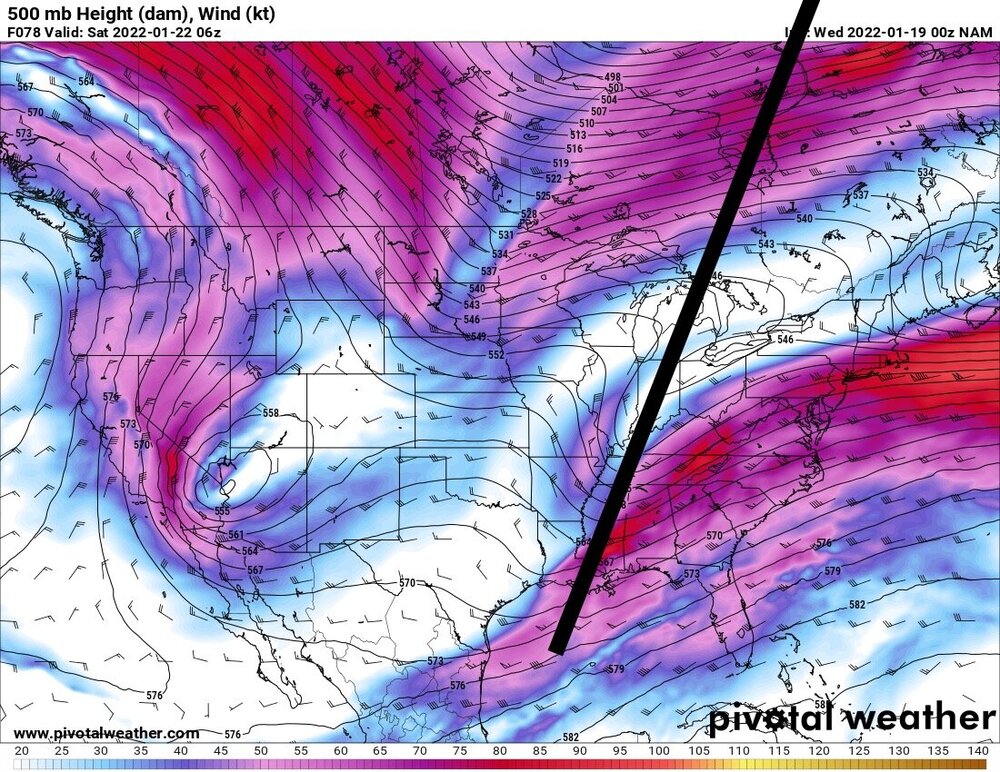
-
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
The key time is from about 54-66 hours. That’s gonna be the make or break on this evolution -
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
Huge jump. And the changes at h5 were fun to watch. Hold it back just a tad and sharpen it just a touch and you’ve got a big storm -
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
That one was easy to see. Watch that h5 trough angle shift about 45 degrees counterclockwise -
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
Well there’s your run of the mill 300 mile move -
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
Yes. Big difference. Trough axis more vertical, much less progressive. Heights rising in front -
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
It’s sharper and deeper, but probably not enough. It is hanging back a tad also -
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
It is -
Thursday 1/20/22 Stat Padder Discussion and Observations
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
Was reading somewhere that the column is cold. That the ground temps are the only issue. If true, that would probably mean a quick transition to snow. -
Thursday 1/20/22 Stat Padder Discussion and Observations
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
It’s all gonna depend on that dry slot on the lee side of the mountains for us. -
Thursday 1/20/22 Stat Padder Discussion and Observations
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
That’s your baby. Let’s ride it and see what happens. -
Thursday 1/20/22 Stat Padder Discussion and Observations
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic

-
Jan 21 - 22 Weekend SE VA and Eastern Shore Snow
WinterWxLuvr replied to stormtracker's topic in Mid Atlantic
I think 36 might be a little early. I was doing all my “looking” at about the 12z Friday time frame